kubeflow adapter repository 기여_2
kubeflow_adapter_repository
지난 글에서 kubeflow adapter repository의 code를 살펴보았다.
kfadapter_Kfconnect에는 kfp 라이브러리의 다양한 코드가 적어져 있으며 pipeline 정보를 얻기 위해 kfadapter_main.py에서는 이 중 일부만 사용 중이기 때문에 구현되어 있는 코드를 가져와 어떤 정보를 가져오는지 확인해 봤다.
-
pipeline id - get_kf_pipeline_id(pipe_name)
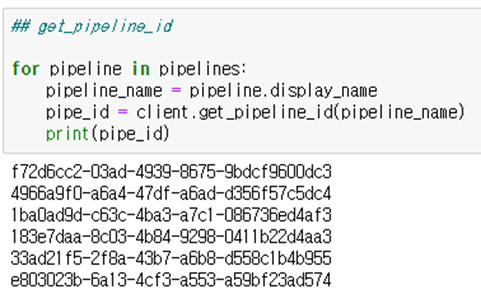
-
Pipeline version - get_pl_versions_by_pl_name(pipeline_name)
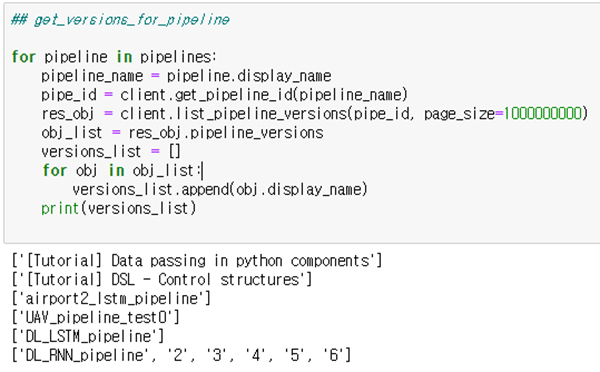
-
pipeline info - get_kf_pipeline_desc(pipe_id)
이 함수에서는 “client.get_pipeline” 함수를 이용해서 pipeline_info의 parameter로 arg, description, id, name 등의 정보를 추출한다.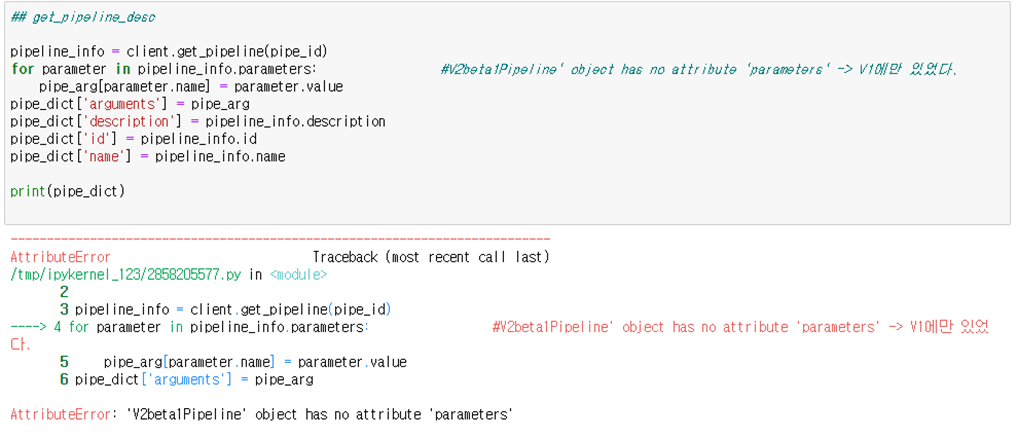 하지만, 이 방법은 kfp V1에서만 지원하는 형식이었고, 현재 container에서 사용하고 있는 kfp의 version도 2.2.0이기 때문에 V2에 관련된 문서를 찾아 보았다.
하지만, 이 방법은 kfp V1에서만 지원하는 형식이었고, 현재 container에서 사용하고 있는 kfp의 version도 2.2.0이기 때문에 V2에 관련된 문서를 찾아 보았다.
Kubeflow Pipeline API Documentation
또한, code 구현에 있어서 kubeflow의 kfp package를 사용할 것이기 때문에 공식 홈페이지에 들어가 pipeline 관련된 함수나 object들의 정보를 싹 뒤져보았다. 참고로, 대부분의 코드들이 kfp.client를 이용하는데 이는 kubeflow의 ui에서 정보를 가져오는 것을 의미한다.


이 내용을 참고하여 pipeline의 정보로 다양한 값들을 뽑아올 수 있었다.
먼저 ‘get_pipeline’을 통해 얻을 수 있는 정보는 다음과 같다.
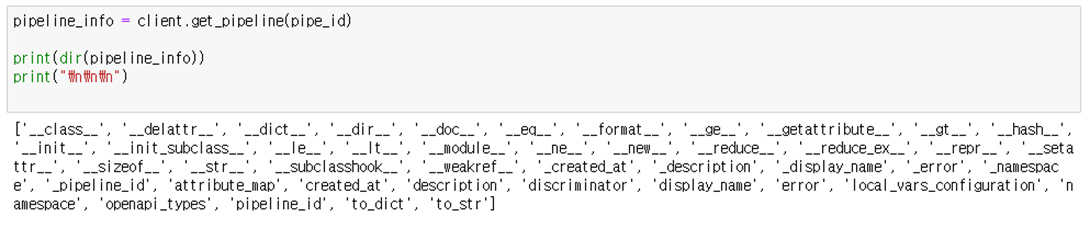
이 중에서 사용할 만한 dir은 다음과 같다.
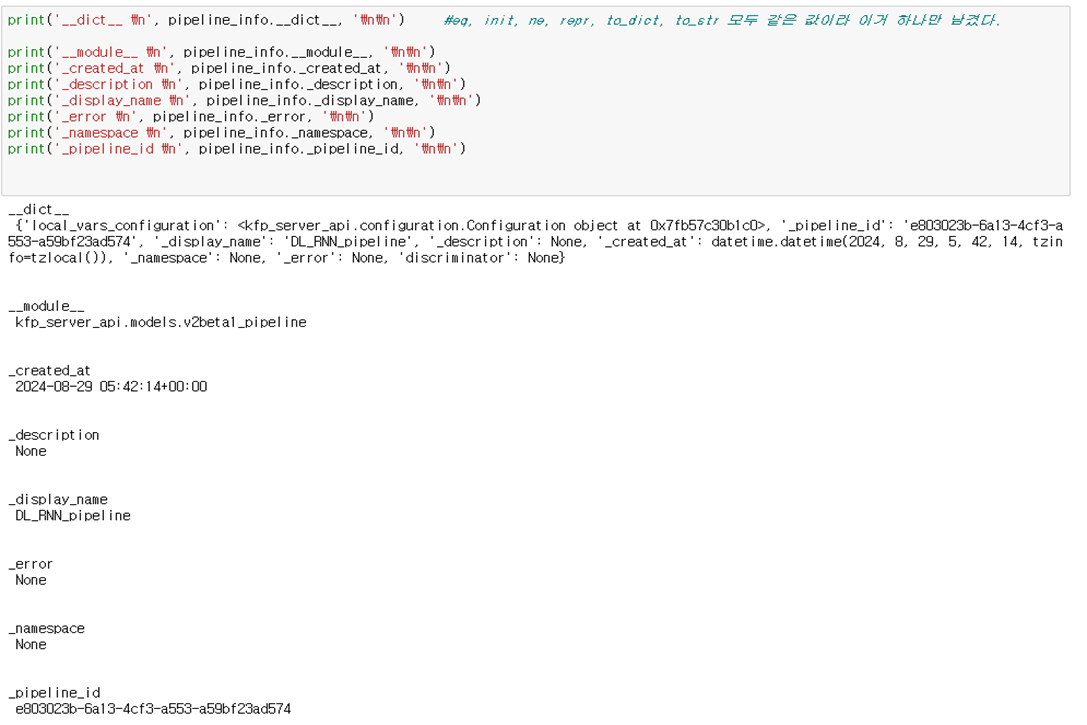
추가로 pipeline의 정보를 V2에서는 pipeline_spec에 저장하고 있다는 사실을 알게 되어 이에 대해 출력보았다. 대신 pipeline의 특정 version에 대한 정보에 대해서만 pipeline_spec을 뽑아 볼 수 있다.
뽑아본 결과 해당 pipeline의 version을 생성할 때 사용되었던 주피터 파일의 코드 내용, pipeline이 실행되는 container 안에서 실행되는 코드 등의 많은 내용이 있었지만 dashboard에 나타낼만한 정보는 없어 사용하지 않기로 했다.
다음은 kfp package 중에서 dashboard에 나타낼만한 정보를 추가로 가져와 보았다.
-
pipeline version의 info
dashboard에서 Pipeline 이름을 동일하게 한 후에 파일을 바꾼 뒤에 생성하게 되면 pipeline version이 생성되는데, 이에 대한 정보도 다음과 같이 추출할 수 있다.
현재 가장 첫 version의 이름은 pipeline 이름으로, 그 뒤는 1씩 더해지는 식으로 되어 구현되어 있는데 이 부분도 수정할 수 있을 것 같다.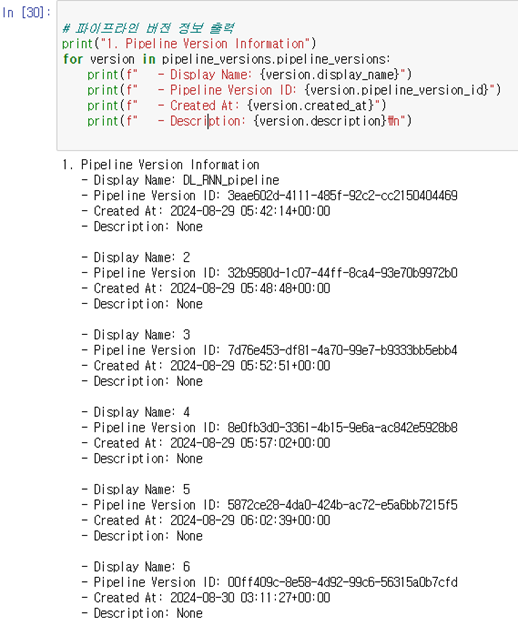
-
pipeline이 실행됬을 때 생기는 단위 : run
Pipeline을 trainingjob에서 실행시킬 때마다 해당 pipeline에 run id가 생성되는데, 다음과 같이 추출할 수 있다.
또한, 각 run id의 세부정보를 확인하면, (client.get_run(run_id)를 이용해서) run의 detail한 정보를 얻을 수 있다.
