2부 4장 ML platform 구조
self service platform
- 사람이 직접 개입하지 앟고 platform 사용자가 필요한 시점에 자원을 갖출 수 있도록 지원하는 기능
- 이를 통해 다양한 역할의 팀이 다른 팀의 의존성을 최소화하면서 협업할 수 있도록 지원하는 것
- 하지만, 여러 문제를 방지하기 위해 적당한 정책이 필요!
- 자원할당 : 할당량에 따라 자원을 배분하고, 할당된 자원에 대해서 책임짐
- 역할 기반의 접근 제어 (role-based access control) : 역할에 맞는 사용자 만이 그들이 관리하는 자원에 접근할 수 있음.
- 같은 platform에서 많은 프로젝트가 실행되고 있기 때문에, 서로의 처리 작업을 격리하여 충돌이 없어야함
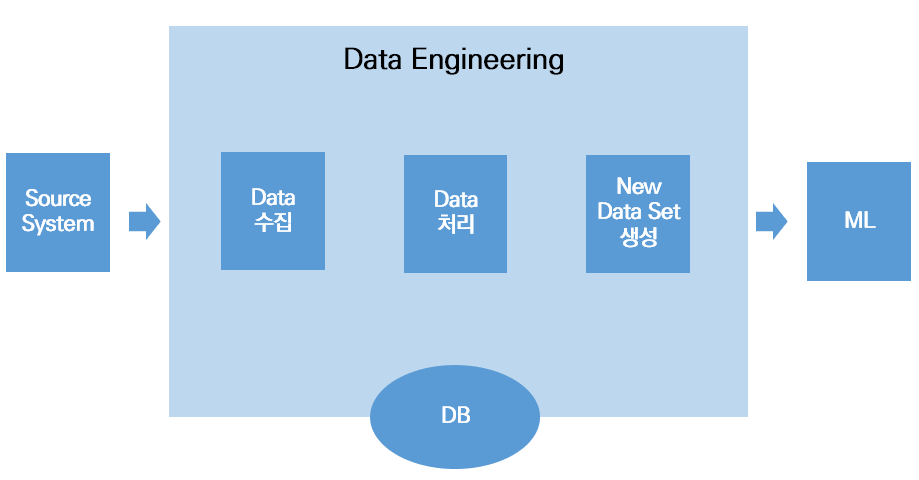
Data Engineering 구성요소
- Data Engineer
- 정제되고 의미 있는 data set을 data 분석가와 data 과학자에게 제공하기 위해 raw data를 수집하고 처리하는 software를 다루는 과정
- ML project의 Data Engineering 영역
- data engineering vs feature engineering
- data engineering : 현재 feature set에 없는 특정 data를 가져옴
- feature engineering : ML 적용 사례에서 어느 feature가 더 유용한지 결정 (data 과학자)
- 두가지 과정의 협업을 통해 data engineering 영역에서 생성한 data set은 ML 전체 영역에서 feature set으로 사용됨
- feature engineering을 위한 ML platform의 component
- Data 수집
- 팀이 data에 대한 이해를 바탕으로 data source에서 data를 수집하는 소프트웨어를 개발하고 배포하는 과정
- source system에서 data를 읽어오는 동안 source system 성능에 미치는 영향을 고려하도록 ML platform이 workflow schedule을 관리하는 것이 중요
- ML platform은 다양한 방법, 다양한 형테의 data source에서 다양한 모양과 크기의 data를 수집하는 기능이 필요
- data source : SQL(DB), NoSQL(cassandra), streaming(apache kafka), 비정형 data(elastic search), 캐시(Redis), object db(S3 API), …
- Data 변환
- 다양한 source로부터 수집한 data를 ML 모델이 학습 또는 여러 활용 방법에 맞게 원래 형태에서 변환해야함.
- ML platform은 쉽게 data 변환 pipeline을 마늗ㄹ어서 배포할 수 있도록 지원함
- ex) apache spark
- 저장소
- feature engineering 과정에서 임시 data set, 새로운 data set을 저장하기 위한 저장소
- Data 수집
Data Engineering Workflow
- Data engineer가 platform에서 수행하는 workflow
- platform login
- data engineer 인증
- 개발 환경 제공
- data engineer가 CPU, memory, software library 등 자원을 platform에 요청
- data pipeline 제작 (시간소요 가장 큼)
- data 수집과 변환을 위한 code를 작성 및 수정
- code를 통해 dta 유효성을 확인
-
data pipeline 실행
**Data Engineering의 결과로 정제된 Dataset얻을 수 있음!**
model 개발 구성 요소
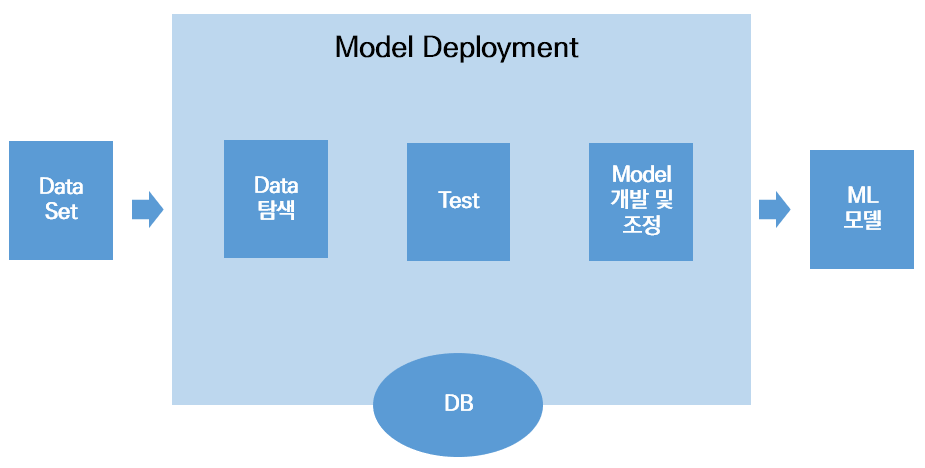
- data 탐색
- 시험
- 추적
- model 개발과 조정
- model 레지스트리
- 저장소
보안, 모니터링과 자동화
-
data pipeline 실행
-
model 배포
-
모니터링
-
보안과 정책
-
소스 코드 관리
**Data set을 이용하여 결과로 model 개발할 수 있음!**