1부 2장 MLOps
머신러닝과 기존 프로그래밍의 비교 (MLOps가 해결해야할 ML의 단점)
- ML의 입력 : code(model의 학습을 위한), data
- 기존 프로그래밍은 code만 입력임
- data set : model 자체가 data set에 매우 의존적임
- data set은 양이 매우 많아 version 관리도 힘듬
- 해결 방법 : 데이터 hash를 활용하기 위해 Git을 사용
- S3, DVC
- ML 프로젝트는 더 많은 협업이 필요
- 각 팀이 서로 이해할 수 없는 점들이 있음
- 데이터 과학자는 배포를, 운영팀은 머신러닝 모델을 모를 수 있음
- ML은 model 개발과정이 추가되어 전체 기간에 큰 영향을 줌
- 다양한 모델이 개발되고, 각 모델의 성능을 테스트하고 비교하는 시간이 길어짐
- 이 중 1개의 모델만 결정되어 운영에 사용됨
- ML model은 학습주기가 굉장히 길기 때문에 이 지연을 효율적으로 사용해야함
- ML model은 data set의 영향을 많이 받음
- Model Drift, Outlier 모니터링 해야함
- 위의 이상을 감지했을 때 알림을 전송하거나 자동화된 process를 trigger하면 좋음
DevOps 장점
- ML project에 사용되는 많은 코드들을 빌드하고 패키징하며, 이를 잘 활용할 수 있도록 적당한 규모로 배포해야함
- DevOps는 CI/CD에 적용할 수 있으며 자동화된 소프트웨어 패키징, 테스트, 보안, 배포, 모니터링을 지원함
MLOps 이해
- MLOps : ML, Data engineering, DevOps의 교집합
- 이에 더해 확장성 좋고, 신뢰성, 감시능력을 지님
-
ML project lifecycle

- 문제의 정형화와 성공 지표 정의
- 주어진 문제를 ML을 통해서 해결할 수 있는지 평가
- model의 성공 여부를 판단하기 위한 기준 정의
- 데이터 수집, 정제 레이블
- data가 model 학습에 사용될 수 있는지 평가
- data engineer의 역할
- 데이터 수집, 수집 데이터의 정제, 데이터 레이블 설정
- FE (Feature Enginneering)
- 원시 data를 문제와 관련된 feature로 변환
- 모델 빌드와 조정
- 다양한 model과 hyper parameter에 대한 test
- 주어진 data set으로 model을 test하고 각 반복마다 결과를 비교하여 모델을 선정
- 모델 검증
- model 학습에 사용하지 않았던 새로운 data를 이용해 모델을 검증
- overfitting을 피함
- bias 검증
- 모델 배포
- model 저장소에서 model을 선택하여 패키지로 만들고 활용할 수 있도록 배포
- 기존의 DevOps process를 사용해 model이 서비스할 수 있도록 집중
- Model as a Service (MaaS) : model이 REST 서비스가 가능하게 만드는데 집중
- 라이브러리 형태로 배포하기도 함
- 모니터링과 유효성 검증
- 지속적으로 응답시간, 예측 정확성, 입력데이터가 학습데이터가 유사한지 확인
- 문제의 정형화와 성공 지표 정의
-
ML project lifecycle (Quick feedback loop)
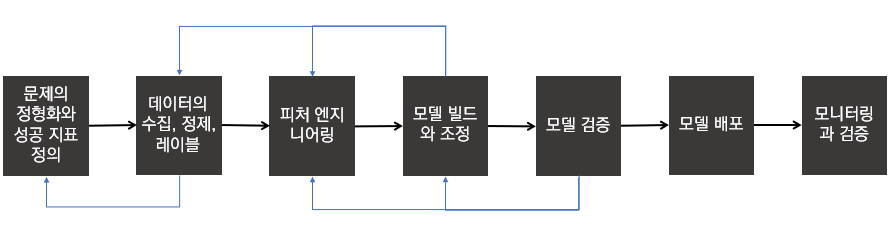
- 데이터 수집, 정제, 레이블 단계의 검사점
- 실제 데이터에 오류가 있는 경우
- 데이터에 대한 이해 높임, 프로젝트 성공 기준 재설정, 데이터가 없어 프로젝트 종료
- 추가적인 데이터 셋 찾기도 함.
- 모델 빌드와 조정 단계의 검사점
- feature가 의도한 지표들을 달성하기 위해선 충분하지 않음
- 새로운 feature를 찾거나, 원시 데이터를 다시 확인함
- 모델 검증 단계의 검사점
- 불량한 지표를 통해 모델을 조정, 추가 feature를 찾음
- 모델 모니터링과 검증 단계의 검사점
- 모니터링과 검증을 통해 모든 기준점으로 다시 돌아갈 수 있음
- 데이터 수집, 정제, 레이블 단계의 검사점
-
ML project lifecycle (협업)
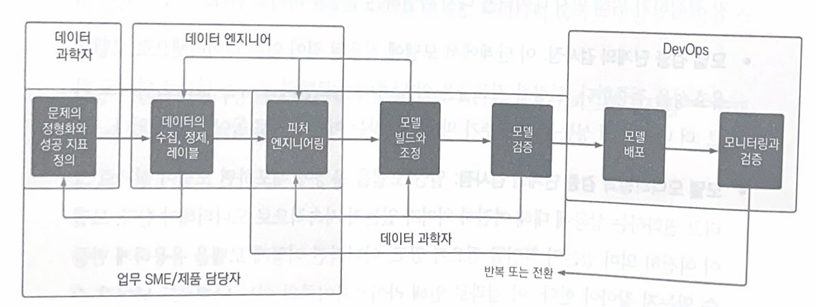
머신러닝 프로젝트에서 OSS의 역할
- 오픈소스가 중요하다!
kubernetes에서 머신러닝 프로젝트 운영하기
- 머신 러닝 시스템을 구축하기 위한 기초로써 채택
- 어디서나 운영할수 있는 portability
- 다양한 종류의 작업 부하를 감당할 수 있음
- 추상화 능력으로 cloud에서도 운영할 수 있음
REST(Representational State Transfer)
- 정의
- 웹 서비스 아키텍처 스타일
- 클라이언트와 서버 간의 상호작용을 간소화
- 웹 서비스의 확장성과 성능을 높이기 위해 설계
- 주로 HTTP 프로토콜을 사용하여 자원을 관리하고 전송하는 방식
- 원칙
- Resource 기반 구조
- REST는 모든 것을 자원으로 간주
- 자원은 URI(Uniform Resource Identifier)를 통해 식별됨
- 표현
- 자원은 JSON, XML을 사용하여 표현되며, 이를 이용해 server와 client가 data를 주고 받음
- 상태 없음(Stateless)
- RESTful 서비스는 상태 비저장(stateless)
- 각각의 HTTP 요청은 독립적이며, 서버는 이전 요청의 상태를 유지하지 않고, 이는 확장성과 안정성을 높이는 데 기여함.
- HTTP 메서드
- REST는 HTTP 메서드를 사용하여 자원에 대한 작업을 정의
- GET: 자원의 조회
- POST: 자원의 생성
- PUT: 자원의 전체 갱신
- PATCH: 자원의 부분 갱신
- DELETE: 자원의 삭제
- REST는 HTTP 메서드를 사용하여 자원에 대한 작업을 정의
- 캐시 가능(Cacheable)
- RESTful 아키텍처는 응답을 캐시할 수 있음.
- 적절한 캐시 제어 메커니즘을 통해 네트워크 효율성을 향상시킴
- 계층화 시스템(Layered System)
- 클라이언트와 서버 사이에 중간 서버를 둔 계층화를 구조로 통신 가능
- 이를 통해 보안, 로드 밸런싱 등의 기능 추가하는데 유용
- Resource 기반 구조