1부 1장 ML
ML
- 머신러닝
- 목적 : 유용한 답이나 기댓값을 얻기 위해 최적의 파라미터를 결정
- 수단 : 모델 (데이터, 알고리즘)
- 머신러닝이 도출한 답은 “모호함”을 지님
- 문제를 풀기 위해 명확한 명령어를 사용하기 어려울 때 유용 (ex. computer vision)
- AI > 머신러닝 > 딥러닝
- 머신러닝의 가치 실현
- 이 책에서는 Kubernetes를 이용하여 OSS를 배포하고, 이를 이용해 머신러닝 프로젝트 운영에 숨어있는 문제를 예방할 것.
- 데이터의 중요성
- 보통 머신러닝 개발 시 모델에만 집중하고 사용하는 데이터에는 집중하지 않음
- 데이터의 유효성과 정제가 중요
-
머신러닝 시스템 구성 요소
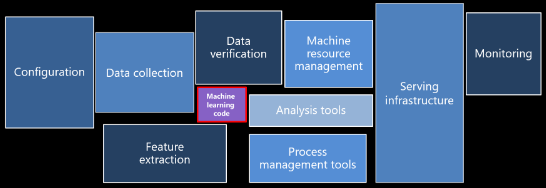
- 데이터 수집, 데이터 검증
- 데이터는 다양한 모양과 크기로 들어옴
- 다양한 데이터 소스와 형식을 가진 데이터를 수집하여 변환하고 처리할 수 있는 기술이 필요.
- 특징 추출, 분석
- 탐구 데이터 분석 (EDA, Exploratory Data Analysis)
- 데이터를 처리하는데 시간을 투자하기 전에 먼저 데이터에 대한 이해를 높이기 위해 EDA 진행
- 특징 추출 (Feature Extraction)
- 실험을 통해 일련의 데이터 속성을 정의해 나가는 절차
- 속성들 중 무관하거나 버려야 할 것들인지를 판단해 나감
- feature set : 관련있는 특성만 포함하고 있는 데이터 셋만을 골라내어 학습 또는 fitness function에서 사용할 수 있는 형식의 데이터 set
- feature engineering = 데이터 수집 + 특징 추출 + 분석
- 탐구 데이터 분석 (EDA, Exploratory Data Analysis)
- 인프라, 모니터링, 자원관리
- 데이터 처리와 탐색, 모델의 빌드와 학습, 모델 배포를 위한 infra(computer) 필요
- 이러한 infra 자원을 최적화 하기위해 모니터링해야함
- 모델 개발
- 사용할 수 있는 feature의 data가 준비되면, 모델을 생성해야함
- 모델은 다양한 알고리즘과 파라미터를 사용한 반복 작업을 요구함
- 모델의 학습과 시험을 단순화하고, 실험 결과와 모델을 쉽게 공유할 수 있는 도구가 필요 (모델의 분류, 승인 및 배포)
- 프로세스 관리
- 모델의 배포와 프로세스 모니터링을 자동화하는 과정
- 총정리
- 데이터 가져오기와 저장 및 처리
- 모델의 학습, 조정, 추적
- 모델의 배포와 모니터링
- 데이터 처리, 모델 배포와 같은 반복된 작업의 자동화
- 데이터 수집, 데이터 검증
ML 협업
- 머신러닝 작업을 여러 팀이 협업하고 공통의 플랫폼에서 작업 수행할 수 있는 방법?!!?!?!?
- 데이터 과학자
- 데이터 엔지니어
- 앱 개발자
- IT 운영자
- 업무 분야별 전문가
-
머신러닝 플랫폼 개요 (책 후반부에서 아래 조건을 만족하는 flatporm을 OSS를 이용해 만들어볼 예정)
- 머신러닝 플랫폼 구성요소
- 더 빠른 개발, 머신러닝 모델의 배포와 데이터 파이프라인을 지원하는 구성요소로 이루어짐
- 완전한 환경
- 데이터, 머신러닝, 앱의 lifecycle의 관리, 관찰이 가능한 E2E service 제공해야함 2. 공개된 표준 기반의 개발
- 빠르게 변화하는 요구사항에 맞춰 추가적으로 개산하고 최적화할 수 있어야함 3. 자동 서비스
- 소프트웨어 배포를 위한 하드웨어 요청을 즉각 반응해야함
- 기업 정책에 맞게 자원파악하고 사용 끝난 자원을 반환하는 과정을 자동화해야함
- 더 빠른 개발, 머신러닝 모델의 배포와 데이터 파이프라인을 지원하는 구성요소로 이루어짐
- 머신러닝 플랫폼 기술 (머신러닝 플랫폼에 필요한 능력들)
- 워크플로 자동화
- 데이터 엔지니어가 데이터 수집과 준비를 위한 반복적인 작업을 수행할 수 있도록
- 데이터 과학자가 모델의 학습과 모델 배포의 자동화를 조정할 수 있도록
- 보안
- 사업에 악영향을 줄 수 있는 데이터의 누출과 손실을 막을 수 있어야함
- 감시능력
- 전체 또는 하위 시스템을 실시간으로 모니터하기에 충분해야함
- 알림 기능
- 로깅
- 시스템이 예상과 다른 동작을 할 때 오류를 처리하기 위해 중요함
- 데이터 처리와 파이프라인 생성
- 머신러닝은 많은 데이터가 필요하기 때문에 수평적으로 확장 가능한 데이터 처리 및 파이프라인 기능을 포함해야함
- 모델 패키징, 배포
- 데이터 과학자가 운영 시스템에 사용할 앱을 제작하고 배포하는 과정이 안전하다고 보장할 수 없기 때문에 플랫폼은 자동으로 머신러닝 모델을 앱 패키지로 만들어 제공할 수 있어야함
- 머신러닝 lifecycle
- 머신러닝 테스트, 성능 추적, 학습, 시험 메타 데이터 저장, feature set, 모델 버전 등을 관리해야함
- ondemand 자원할당
- 데이터 과학자와 엔지니어가 실행에 필요한 자원을 자동으로 필요한 시점에 받을 수 있어야함
- 워크플로 자동화
- 머신러닝 플랫폼 구성요소